Lucid语言
Lucid是数据流程编程语言,设计用来实验非冯·诺伊曼编程模型。它是William W. Wadge和Edward A. Ashcroft在1976年设计的[1],并描述于1985年的书籍《Lucid, the Dataflow Programming Language》[2]。
| 编程范型 | 数据流程 |
|---|---|
| 設計者 | Edward A. Ashcroft William W. Wadge |
| 发行时间 | 1976年 |
| 主要實作產品 | |
| pLucid | |
| 衍生副語言 | |
| GIPSY, Granular Lucid | |
| 啟發語言 | |
| ISWIM | |
| 影響語言 | |
| SISAL, Pure Data, Lustre | |
pLucid是Lucid的首个解释器。
模型
Lucid使用针对数据计算的需求驱动模型。每个语句都可以理解为一个方程,它定义了一个网络,即处理器和它们之间的数据经此流动的通信线路。每个变量都是值的一个无限流(stream),而每个函数都是一个过滤器或变换器。Lucid最大的创新之处,是能够进行流合成(composition)的迭代,这是通过“当前”值和算子fby(读作followed by)来模拟表述的。
Lucid基于了一种“历史”(history)的代数,“历史”是数据项的无限序列。在操作上,“历史”可以被认为是一个变量的变更着的值的记录,对“历史”的运算操作比如first和next可以随其名字所提示的那样理解。Lucid最初被构想为一个规矩的、数学上纯粹的单赋值语言,如此其验证将会被简化[3]。但是,数据流程释义在Lucid的演变方向上有着重要的影响[4]。
细节
Lucid从ISWIM继承了where子句作为自己的块结构,从POP-2继承了数据类型。在Lucid中,每个表达式中的变量,都要先在表达式自身的where子句中寻找对应的变量定义,包含仍未约束的变量的表达式,在继续进行(proceed)之前,要等待直到这个变量已经被约束,即等待从输入中获取变量的值。一个表达式如x + y,在返回这个表达式的输出之前,将等待直到x和y二者都成为约束的。这样有一个重要结果,避免了更新有关值的显式的逻辑,导致了相较于主流语言的先声明再引用方式有大量的代码简约。
在Lucid中每个变量都是值的流(stream)。算子fby(followed by的助忆码),定义了在前一个表达式之后会出现什么。表达式n = 1 fby n + 1使用fby定义了一个流n,在这个实例中,这个流产生序列[1,2,3,...]。在流中的值,可以通过如下这些算子来寻址取用,假定x是用到的变量:
first x- 取回在流x中的第一个值。每次求值这个表达式都得到同样这个值。x- 取回在流x中当前值。next x- 取回在流x中当前值的下一个值。x asa p- 如果p提供了一个"true"值,则立刻(as soon as)提供x,否则在下一个x和下一个p上继续进行此运算操作。每次求值这个表达式都得到同样这个值。可以想像为它根据控制流p,从流x选取出第一个已经符合条件的值。x whenever p- 如果p提供了一个"true"值,则提供x;接着在下一个x和下一个p上继续进行此运算操作。可以想像为它根据控制流p,从流x过滤出符合条件的所有值。它可以写为助记码wvr。x upon p- 提供x,如果p提供了一个"true"值,则在下一个x和下一个p上继续进行此运算操作,否则在这个x和下一个p上继续进行此运算操作。可以想像为它根据控制流p,在符合条件时放行流x的下一个值,在不符合条件时以重复当前值的方式滞留流x。x attime i- 将流i中的值作为流p中值的位次索引,依次从i取得索引选择流x中指定位次的值。可以想像为它根据索引流i,对流x进行了选取和重组。X is current x- 将流x的当前值保存在X变量中。每次求值X时都得到同样的这个值。典型用于嵌套的内层迭代,它不能直接使用x而导致这个流的当前值顺序前进的情况下,比如后面例子中的指数函数程序等。
计算是通过定义作用在数据的时变流上的过滤器或变换函数来完成的。涉及多个流的函数和运算操作采用逐点(pointwise)释义比如:f(x,y) = [f(x0,y0),f(x1,y1),f(x2,y2),...],在后面例子中进行二个流的归并和串接时,因而在条件表达式if p then x else y fi中需要通过upon对要操作的流进行预处理。
数据结束(end of data)对象用预定义特殊标识符eod表示,iseod eod将返回"true",此外所有的对eod的运算操作都产生eod。错误对象用预定义特殊标识符error表示。index是预定义变量,它是以0开始的自然数序列。此外预定义变量还有true = "true"、false = "false"等。
例子
序列的总和
total
where
total = 0 fby total + x
end
running_avg
where
sum = first(input) fby sum + next(input);
n = 1 fby n + 1;
running_avg = sum / n;
end
fac
where
n = 0 fby (n + 1);
fac = 1 fby (fac * (n + 1));
end
fib
where
fib = 0 fby (1 fby fib + next fib);
end
指数函数

expsum asa next i eq 10
where
X is current x;
i = next index;
term = 1 fby (term / i) * X;
expsum = 0 fby expsum + term;
end
均方根
sqroot(avg(square(a)))
where
square(x) = x*x;
avg(y) = mean
where
n = 1 fby n+1;
mean = first y fby mean + d;
d = (next y - mean)/(n+1);
end;
sqroot(z) = approx asa err < 0.0001
where
Z is current z;
approx = Z/2 fby (approx + Z/approx)/2;
err = abs(square(approx)-Z);
end;
end
prime
where
prime = 2 fby (n whenever isprime(n));
n = 3 fby n+2;
isprime(n) = not(divs) asa divs or prime*prime > N
where
N is current n;
divs = N mod prime eq 0;
end;
end
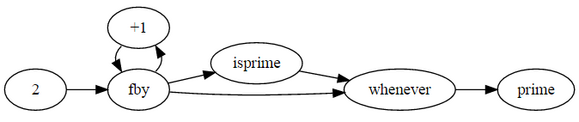
注释:程序代码在图示基本原理上进行了代码优化。
.png)
漢明數
计算升序的正规数的算法经由戴克斯特拉得以流行,有关问题叫做“汉明问题”。Dijkstra计算这些数的想法如下:
- 汉明数的序列开始于数
1。 - 要加入序列中的数有下述形式:
2h,3h,5h,这里的h是序列已有的任意的汉明数。 - 因此,可以生成最初只有一个
1的序列H,并接着归并序列2H,3H,5H,并以此类推。
hamming
where
h = 1 fby merge(merge(2 * h, 3 * h), 5 * h);
merge(x,y) = if xx <= yy then xx else yy fi
where
xx = x upon xx <= yy;
yy = y upon yy <= xx;
end;
end
注意这个程序中归并函数中的upon条件能够起到二个流中可能存在的相同值在结果中只出现一个的效果。
数据流程图

Hamming problem dataflow diagram
.png)
快速排序
下面程序实现了霍尔的快速排序算法,将序列划分为小于基准值(pivot)的元素和不小于它的元素的两个子序列,然后递归的排序这两个子序列,再将结果的两个排好序的子序列串接起来。
qsort(a) = if iseod(first a) then a else follow(qsort(b0), qsort(b1)) fi
where
p = a < first a;
b0 = a whenever p;
b1 = a whenever not p;
follow(x,y) = if xdone then y upon xdone else x fi
where
xdone = iseod x
end
end
数据流程图
+--------> whenever -----> qsort ---------+ | ^ | | | | | not | | ^ | |---> first | | | | | | | V | | |---> less ---+ | | | | | V V ---+--------> whenever -----> qsort -----> follow -----> if-then-else -----> | ^ ^ | | | +--------> next ----> first ------> iseod --------------+ | | | +------------------------------------------------------------+
引用
- ^ Edward A. Ashcroft, William W. Wadge. Lucid—A Formal System for Writing and Proving Programs (页面存档备份,存于互联网档案馆). September 1976. SIAM Journal on Computing 5(3):336-354.DOI: 10.1137/0205029.
Edward A. Ashcroft, William W. Wadge. Lucid: Scope structures and defined functions (页面存档备份,存于互联网档案馆). November 1976. TechnicalReport CS–76–22, Department of Computer Science, University of Waterloo. Published in 1978. - ^ Wadge, William W.; Ashcroft, Edward A. Lucid, the Dataflow Programming Language (PDF). Academic Press. 1985 [28 April 2020]. ISBN 0-12-729650-6. (原始内容存档 (PDF)于2020-03-27).
- ^ Edward A. Ashcroft, William W. Wadge. LUCID, A Nonprocedural Language with Iteration[失效連結]. July 1977. in Communications of the ACM 20(7):519-526.
- ^ Online Historical Encyclopaedia of Programming Languages. [2020-05-02]. (原始内容存档于2020-12-04).